Das Forschungsdatenmanagement von eLabour hat verschieden Aufgaben:
- Soll es Strukturen bieten, welche die Primärforscher: innen in der Durchführung ihrer Studie unterstützen
- Soll es Datensätze erzeugen, welche nach Abschluss der Studie automatisiert in die eLabour Infrastruktur überführt werden können
- Sollen die erzeugten Daten derart strukturiert und bearbeitet werden, dass sie einfach für Dritte nachvollziehbar sind
Um diese drei Ziele zu erreichen hat das FDZ eLabour umfangreiche Prozesse entwickelt, die individuell anpassbar sind und sich damit an die Bedürfnisse der durchführenden Forscher: innen anpassen lassen. Gleichzeitig ist das FDM eng mit den Anforderungen durch den Datenschutz verwoben. Daher war eine gewisse Standardisierung von Nöten um eben diesen Rechnung zu tragen.
Im Optimalfall wird das Forschungsdatenmanagement bereits in der Akquise mitgedacht. Denn auch wenn das FDM studienprozessbegleitend durchgeführt werden kann, so entsteht doch ein gewisser Mehraufwand der im Vorfeld eingepreist werden sollte. Das Forschungsdatenmanagement beginnt mit der Arbeit an der Studie.
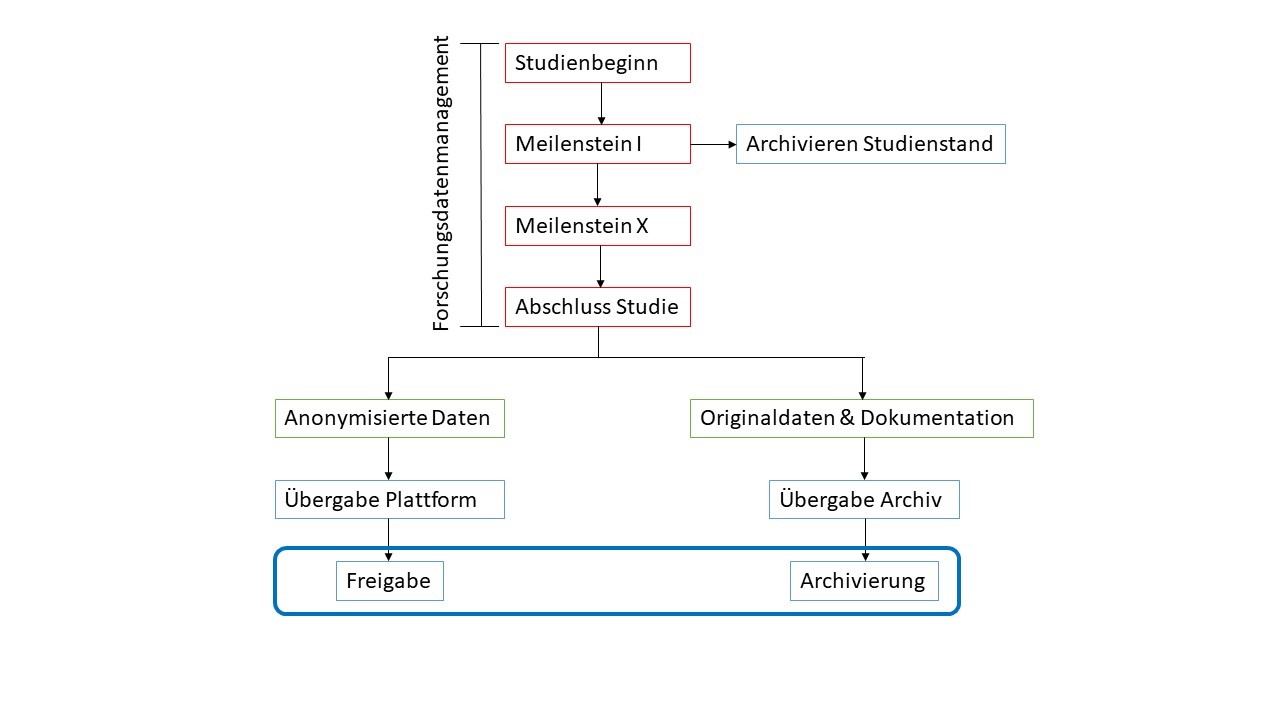
Das Forschungsdatenmanagement basiert steht auf drei Säulen:
Die eLabour Ordnerstruktur wurde entwickelt um die strukturierte Ablage von Daten zu ermöglichen. Des Weiteren kann diese sukzessive befüllt und erweitert werden.
Die hier schematisch dargestellte Ablage ist flexibel anpassbar und auch eine Verschachtelung von Fällen, Wellen und Gruppen sind möglich. Durch die standardisierte Grundstruktur erlaubt die Ordnerstruktur aber auch das automatisierte Einlesen der Daten in die eLabour Plattform. Sie bietet daher zwei große Vorteile:
- erstens können die Daten in der von den Primärfoscher:innen erdachten Studienlogik strukturiert abgelegt werden
- zweitens können diese automatisiert in die digitale Infrastruktur überführt werden welche wiederrum die Studienlogik abbildet
Um den hohen Datenschutzanforderungen durch die DSGVO Rechnung zu tragen müssen alle Dokumente die zur Nachnutzung bereitgestellt werden sollen, anonymisiert werden. Die geringste Form der Anonymisierung ist dabei die Pseudonymisirung, das heißt, dass alle Namen von erwähnten und Interviewten Personen durch Pseudonyme ersetzt werden. Eine weitreichendere Anonymisierung einzelner Passagen kann in Einzelfällen notwendig sein. Diese Anonymisierungsprozesse können gleichzeitig mit der allgemeinen Arbeit mit den Dokumenten geschehen. Es ist ebenfalls denkbar, dass dieser Arbeitsschritt von Hilfskräften durchgeführt wird und/oder alle Klarnamen bereits während der Transkription markiert und/oder ersetzt werden.
Ziel der Bearbeitung ist es nicht alle risikohaften Passagen aus dem Material zu entfernen, sondern eine Reidentifikation der Befragten und genannten Personen zu verhindern. Greift man mit Anonymisierungsmaßnahmen zu tief ins Material ein wird dieses unbrauchbar. Die Primärforscher:innen können sich jedoch darauf verlassen, dass das eLabour DATENSCHUTZKONZEPT auch von den Sekundärnanalytiker:innen eingehalten wird, da diese sich dazu vertraglich verpflichtet haben und es sich ausschließlich um redliche Wissenschaftler:innen handelt.
Die festgelegten Pseudonyme sowie weiterreichende Anonymisirungsmaßnahmen sollten in Schlüsseltabellen festgehalten werden. Diese werden selbstverständlich nicht zur Nachnutzung freigegeben, sondern vor dem Ingest im ORIGINALDATENARCHIV abgelegt.
Herzstück des eLabour Datenschutzkonzeptes bilden die Risiko- und Freigabeklassen der einzelnen Dokumente. eLabour arbeitet mit einem fünfstufigen Risikoklassensystem.

Die Einstufung der Dokumente in einer der fünf Risikoklassen regelt die Zugriffsmöglichkeiten auf eben dieses Dokument. Die Risiko- und Freigabeklassen müssen ebenfalls dokumentiert werden, da ohne sie keine Freigabe der Dokumente erfolgen kann.
Was auf den ersten Blick als ein gesteigerter Aufwand erscheint ist in der Arbeitsrealität gut umsetzbar. Bei der Arbeit mit dem Material bekommen die Primärforscher:innen einen sehr genauen Eindruck von der Risikohaftigkeit einzelner Dokumente. Die typische Risikoklasse ist die FGK III, in diese fallen alle Dokumente in denen zwar risikohafte Passagen (z.B. personenbezogene Daten) enthalten sind, bei denen die Interviewten jedoch nicht reidentifiziert werden können.
eLabour berät Sie gerne zu den für ihre Studie notwendigen FDM-Prozessen. Um eine optimale Gestaltung und Bepreisung des FDM Prozesses zu ermöglich empfiehlt es sich, bereits zur Projektakquise Kontakt zu eLabour aufzunehmen.